Основы мониторинга в Linux

В деятельности любой современной компании крайне важную роль играет IT-инфраструктура, которая может включать Wi-Fi роутеры, принтеры, ноутбуки, файловые серверы, сетевое оборудование, серверы и многое другое, установленные либо в офисе самой компании, либо в центре обработки данных. Таким образом, непрерывность работы той или иной организации в значительной степени зависит от стабильности собственной информационной сети и инфраструктуры. Именно здесь на помощь приходит системное и сетевое администрирование, в том числе, мониторинг системных ресурсов.
Для поддержания стабильности всей инфраструктуры системный и сетевой администратор в первую очередь выполняет следующие задачи:
- обеспечивает надлежащую и бесперебойную работу оборудования.
- обеспечивает работоспособность всех узлов.
- обеспечивает максимальную производительность приложений, находящихся на серверах.
- удостоверяется, что серверы имеют необходимый размер и/или могут масштабироваться по требованию для обработки рабочей нагрузки.
- удостоверяется, что система не испытывает недостаток ресурсов.
Для выполнения поставленных задач ключевую роль играет мониторинг системы. Это особенно важно, т.к. это является основным компонентом любой компьютерной сети. Мониторинг компьютерной системы обычно включает в себя установку управляющего программного обеспечения на устройстве, которое нужно отслеживать и которое прошло аутентификацию на сервере мониторинга. Не существует единого определения понятия «мониторинг системы», т.к. оно меняется в зависимости от того, как его использует системный администратор. В самом простом виде данное понятие может быть определено как процесс беспрерывного сканирования и сбора различных данных из различных систем в течение определенного промежутка времени.
Зачем нужен мониторинг системы?
Существует много причин, почему необходимо выполнять мониторинг. К ним относятся:
- Доступ к состоянию всей инфраструктуры в режиме онлайн.
- Анализ долгосрочных тенденций.
- Сравнение или проведение экспериментов (например, какая подсистема хранения лучше для моей базы данных – MyISAM или InnoDB?)?
- Оповещение (уведомление о превышение установленных лимитов).
- Построение информационных панелей (графов, карт состояния сети и т.д.): визуализация данных (связано с пунктом 2). Помогает увидеть тенденции, неочевидные в их исходном необработанном виде.
- ретроспективный анализ: взаимосвязь между полученными оповещениями и другими данными, собранными за тот же промежуток времени.
- Сокращение затрат. Например, один из серверов, развернутый в облаке, используется не в полную силу. Можно переместить приложение, установленное на нём, на сервер меньшего размера либо продолжать устанавливать на него новые приложения, не создавая для них новый сервер
- Преобразование собранных данных в бизнес-аналитику.
- Отслеживание проблем безопасности.
- Проактивные меры защиты (а не реактивные).
Мониторинг оперативной памяти
В каждой версии Linux есть программа под названием free , при запуске которой отображается объем свободной и используемой памяти системы.
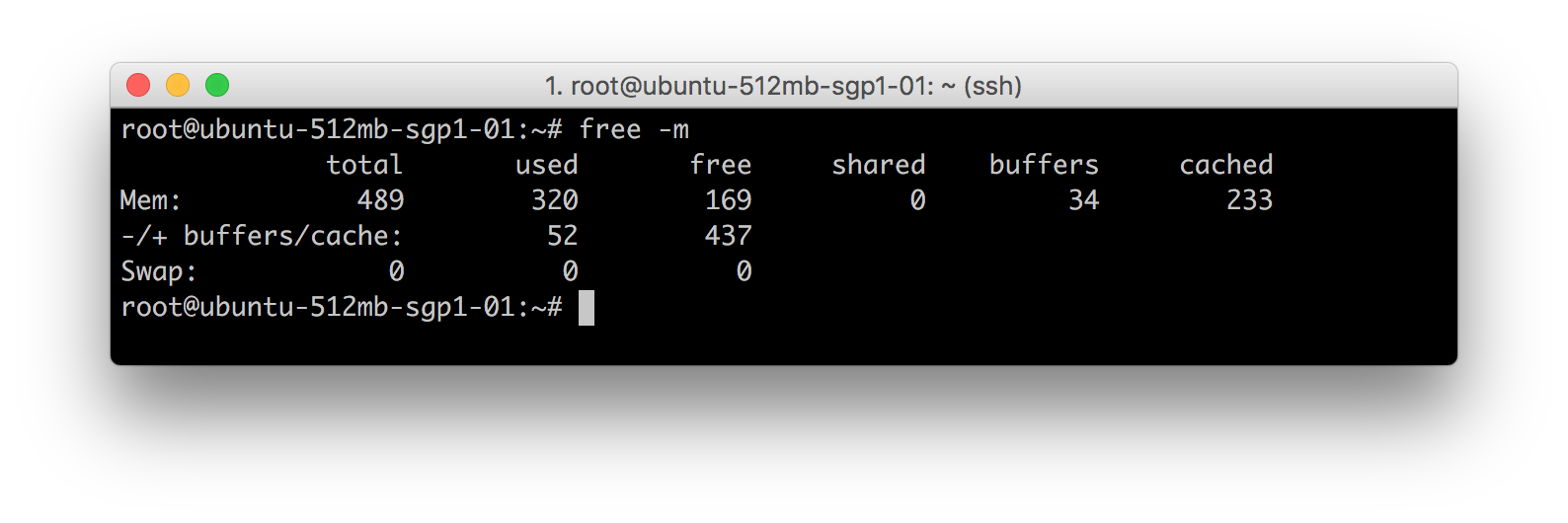
На изображении сверху видно, что программа free используется с опцией -m для отображения значений в мегабайтах. Ниже мы даем пояснение некоторым элементам:
Строка 2: Mem: 489 320 169 0 34 233
- 489: объем физической/оперативной памяти, доступный на данном устройстве.
- 320: объем физической/оперативной памяти, используемый системой. Сюда также входят буферы и кэш-память
- 169: общий объем физической/оперативной памяти, доступный для запуска нового процесса.
- 0: совместно используемая физическая/оперативная память. Данная колонка является устаревшей и будет удалена в следующих версиях программы
- 34: общий объем физической/оперативной памяти, буферизованный различными приложениями в системе.
- 233: общий объем физической/оперативной памяти, используемый для кэширования данных в дальнейших целях. Эту память можно восстановить или перераспределить.
Строка 3: -/+ buffers/cache: 52 437
- 52: фактический объем используемой физической/оперативной памяти (получается при вычитании буферов и кэш-памяти)
Математические подсчеты:
- Используемая оперативная память: 320
- Используемые буферы: 34
- Используемая кэш-память: 233
Фактический объем используемой оперативной памяти составляет 320-(34+233)=53
Строка 4: Swap: 0 0 0
Данная строка показывает сведения о файле подкачки. В нашем случае на сервере нет доступной области подкачки, поэтому программа выдает нули. Установка области подкачки всегда опциональна. Swap – это виртуальная память, создаваемая на жестком диске для виртуального увеличения объема оперативной памяти.
Мониторинг ЦП
Помимо программы free , которая используется для проверки использования памяти, существует также ряд различных аналогичных инструментов для просмотра использования ЦП (например, top, htop, uptime, tload и т.п.).
Начнем с наиболее комплексной программы – программы top. В ней фактически отображаются процессы в Linux. Также дается динамическое представление работающей системы в режиме реального времени. Программа может отображать как сводную информацию о системе, так и список процессов и потоков, управляемых в данный момент ядром Linux.
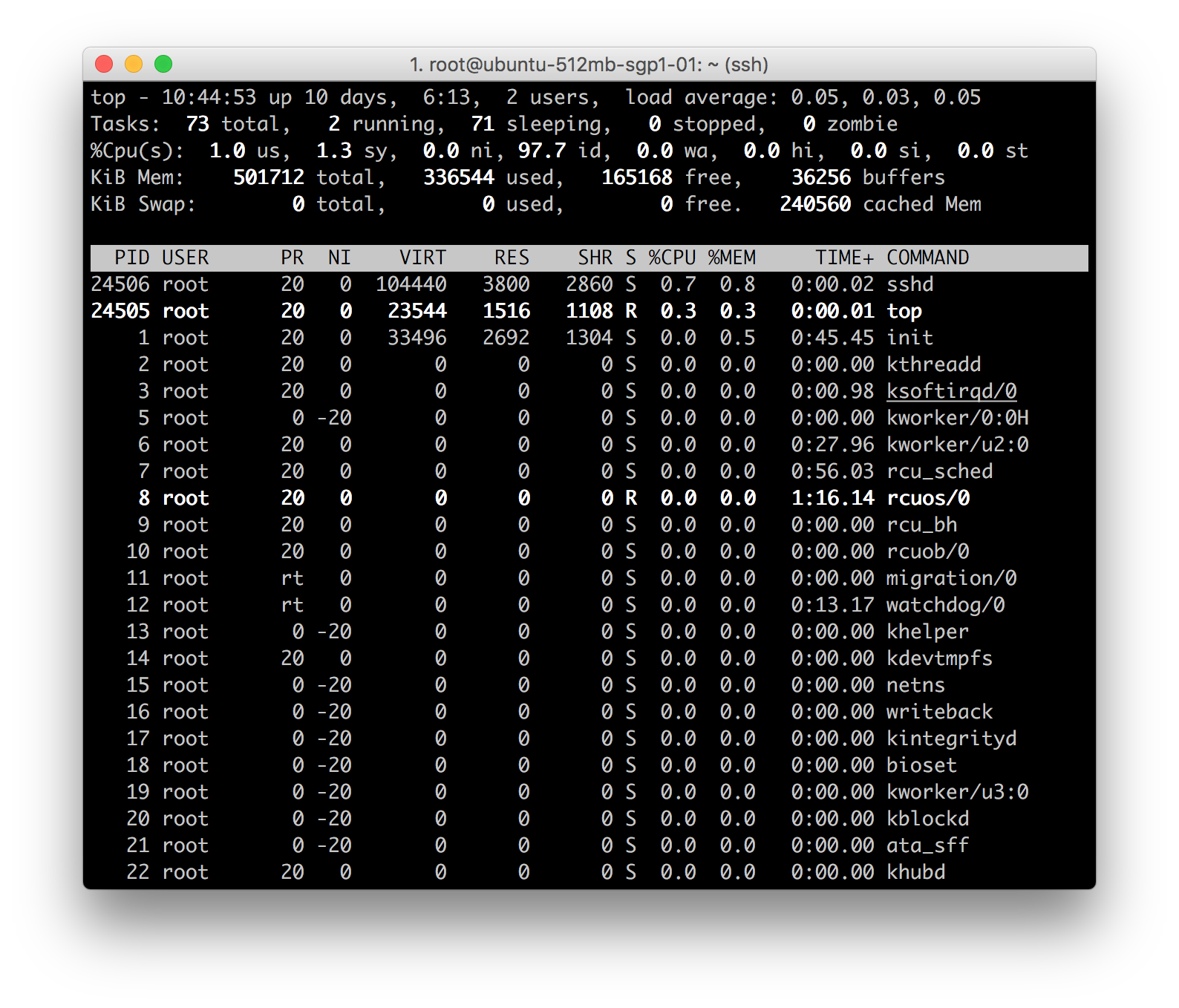
Строка 1: top - 10:52:23 up 10 days, 6:20, 2 users, load average: 0.05, 0.03, 0.05
- текущее время (10:52:23)
- время работы устройства (up 10 days, 6:20 – 10 дней, 6 часов, 20 минут)
- пользователи, вошедшие в систему (2 users – 2 пользователя)
- средняя нагрузка на систему (load average): значения 0.05, 0.03, 0.05 относятся к последним 1, 5 и 15 минутам соответственно.
Строка 2: Tasks: 71 total, 1 running, 70 sleeping, 0 stopped, 0 zombie
- Общее число работающих процессов (71 totals – 71 процесс)
- Запущенные процессы (1 running – 1 запущенный процесс)
- Процессы в режиме ожидания (70 sleeping – 70 процессов в режиме ожидания)
- Остановленные процессы (0 stopped – 0 остановленных процессов)
- Процессы-зомби, ожидающие завершения от родительского процесса (0 zombie – 0 процессов-зомби)
Строка 3: %Cpu(s): 0.3 us, 0.0 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
Данная строка показывает, как используется процессор. Если сложить все значения, данные в процентах, то в сумме мы получим 100% от ЦП. Рассмотрим эти значения по порядку:
- Пользовательские процессы (0.3% us)
- Системные процессы (0.0% sy)
- Процессы ЦП с приоритетом обновления (0.0% ni)
- Неиспользуемый процент ЦП (99.7% id)
- Процессы ЦП, ожидающие операций ввода-вывода (0.0% wa)
- Обслуживание аппаратных прерываний (0.0% hi – запрос аппаратного прерывания)
- Обслуживание программных прерываний (0.0% si – программное прерывание)
- Процент ЦП, «украденный» с виртуального устройства гипервизором для выполнения других задач (например, для запуска другой виртуальной машины). Без виртуального устройства на рабочем столе и сервере будет выдаваться 0 (0.0% st — Украденное время)
Строка 4 and 5:
KiB Mem: 501712 total, 355316 used, 146396 free, 38412 buffers
KiB Swap: 0 total, 0 used, 0 free. 257832 cached Mem
4 и 5 строки соответственно показывают использование физической памяти (ОЗУ) и файла подкачки (такие же результаты, как и в программе free).
И последнее, что выдается (по умолчанию) при просмотре использования ЦП, – это процессы, используемые в настоящее время. Каждый из столбцов содержит различную информацию:
- PID – ID процесса (1)
- USER – пользователь, который выполняет процесс (root)
- PR – приоритет процесса (20)
- NI – приоритет процесса (0)
- VIRT – виртуальная память, используемая процессом (33496)
- RES – физическая память, используемая процессом (2692)
- SHR – совместно используемая память процесса (1304)
- S – S – показывает статус процесса: S – в режиме ожидания, R – запущенный, Z – зомби (S)
- %CPU – процент ЦП, используеый процессом (0.0)
- %MEM – процент ОЗУ, используемый процессом (0.5)
- TIME+ – общее время работы процесса (0:45:.48)
- COMMAND – название процесса (init)
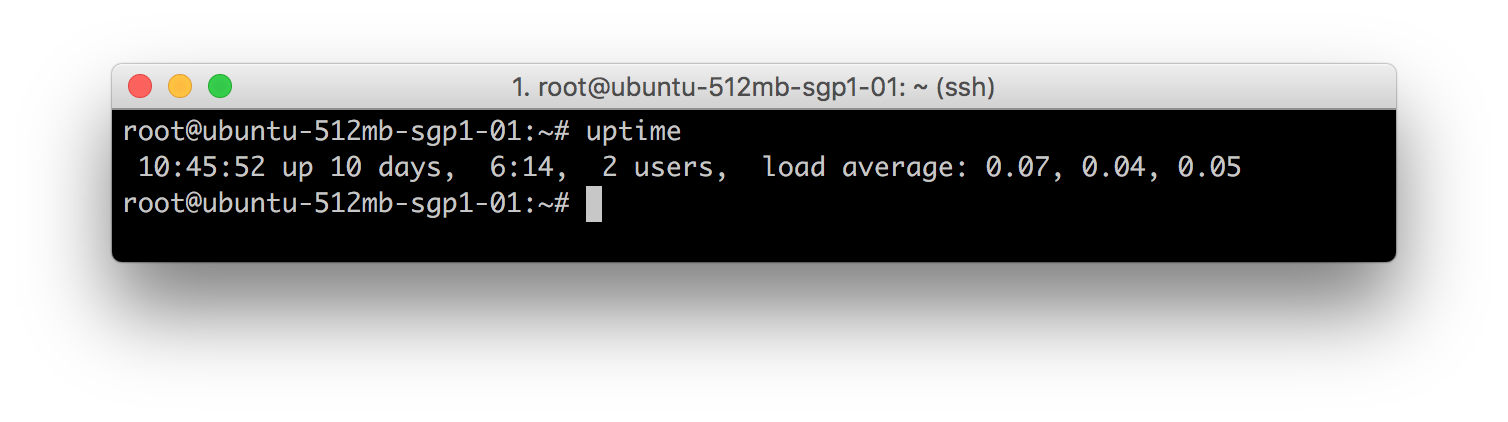
Программа Uptime. Предоставляет следующую информацию одной строкой: текущее время, время работы системы, количество вошедших в систему пользователей и среднюю нагрузку на систему за последние 1, 5 и 15 минут.
Программа tload. Позволяет интерактивно следить за процессом. htop похожа на программу top, но при этом htop можно прокручивать как вертикально, так и горизонтально, что позволяет увидеть все запущенные в системе процессы вместе с их полными командными строками.
htop program. It is an interactive process viewer. It is similar with top but allows it is allowed to scroll vertically and horizontally, so all the processes running on the system can be seen, along with their full command lines.
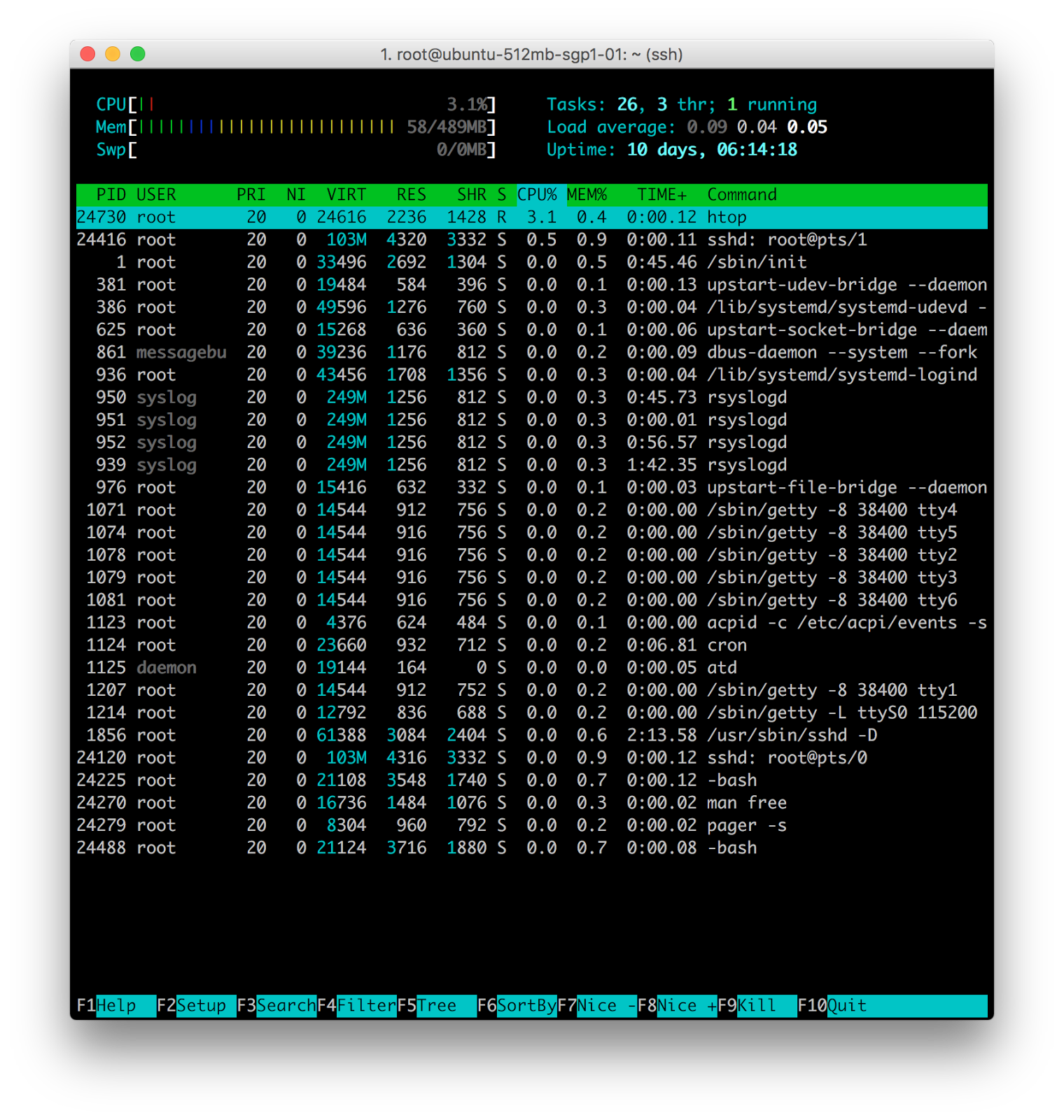
Нагрузка на систему
Из предыдущего материала мы увидели, что нагрузка на систему присутствует во всех трех программах, представленных выше (варьируются только значения, полученные в разное время). Все три случая объединяет то, что в каждом из них мы имеем по три значения. Что же означают эти числа?
Например, возьмем значения 0.07 0.04 0.05. Их можно прочесть как:
- Средняя нагрузка за последнюю минуту: 0.07
- Средняя нагрузка за последние 5 минут: 0.04
- Средняя нагрузка за последние 15 мину: 0.05
Средняя нагрузка – это среднее число процессов, запущенных или ожидающих выполнения за 1, 5 и 15 минут. Эти значения не зависят от количества процессорных ядер, но чем больше ядер, тем больше процессов могут быть запущены одновременно. Так, например, если на устройстве с одним ядром средняя нагрузка равна 3, то устройство перегружено, в то время как для 4-ядерного компьютера это нормальная рабочая нагрузка.
Мониторинг диска
Как правило, при рассмотрении производительности диска всегда отслеживаются два параметра: IOPS и дисковое пространство. Под дисковым пространством понимается количество используемого пространства, а IOPS является стандартной единицей измерения операций ввода/вывода в секунду. Простым языком, IOPS – это операции чтения/записи, выполняемых диском. На устройствах Linux есть также встроенные программы, которые отслеживают эти два параметра:
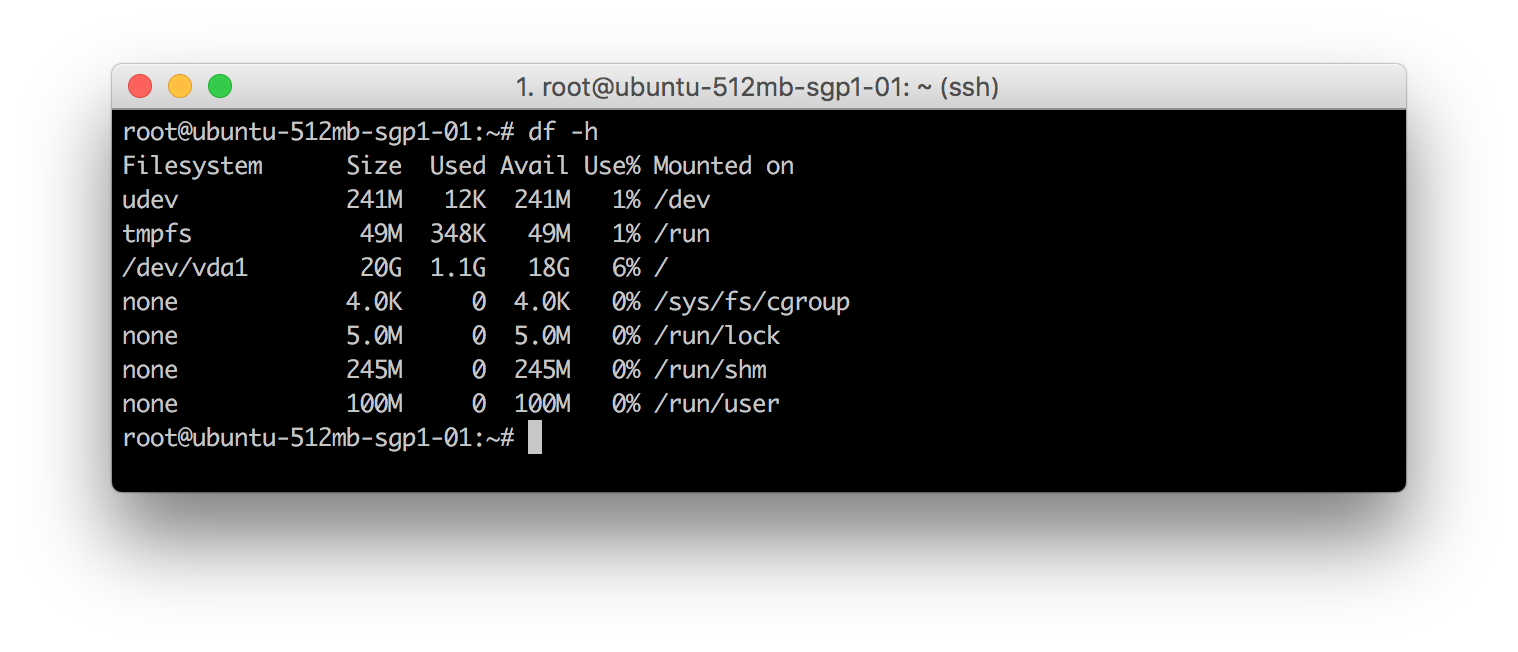
программа df. Сообщает об использовании дискового пространства файловой системы.
Данная программа используется с опцией -h, которая позволяет пользователю прочесть значения. Названия столбцов в основном не требует разъяснений. Filesystem – созданный раздел, Mounted On – точка подключения, в которой тот или иной раздел доступен.
Программа iotop. Простой монитор операций ввода/вывод, похожий на программу top.
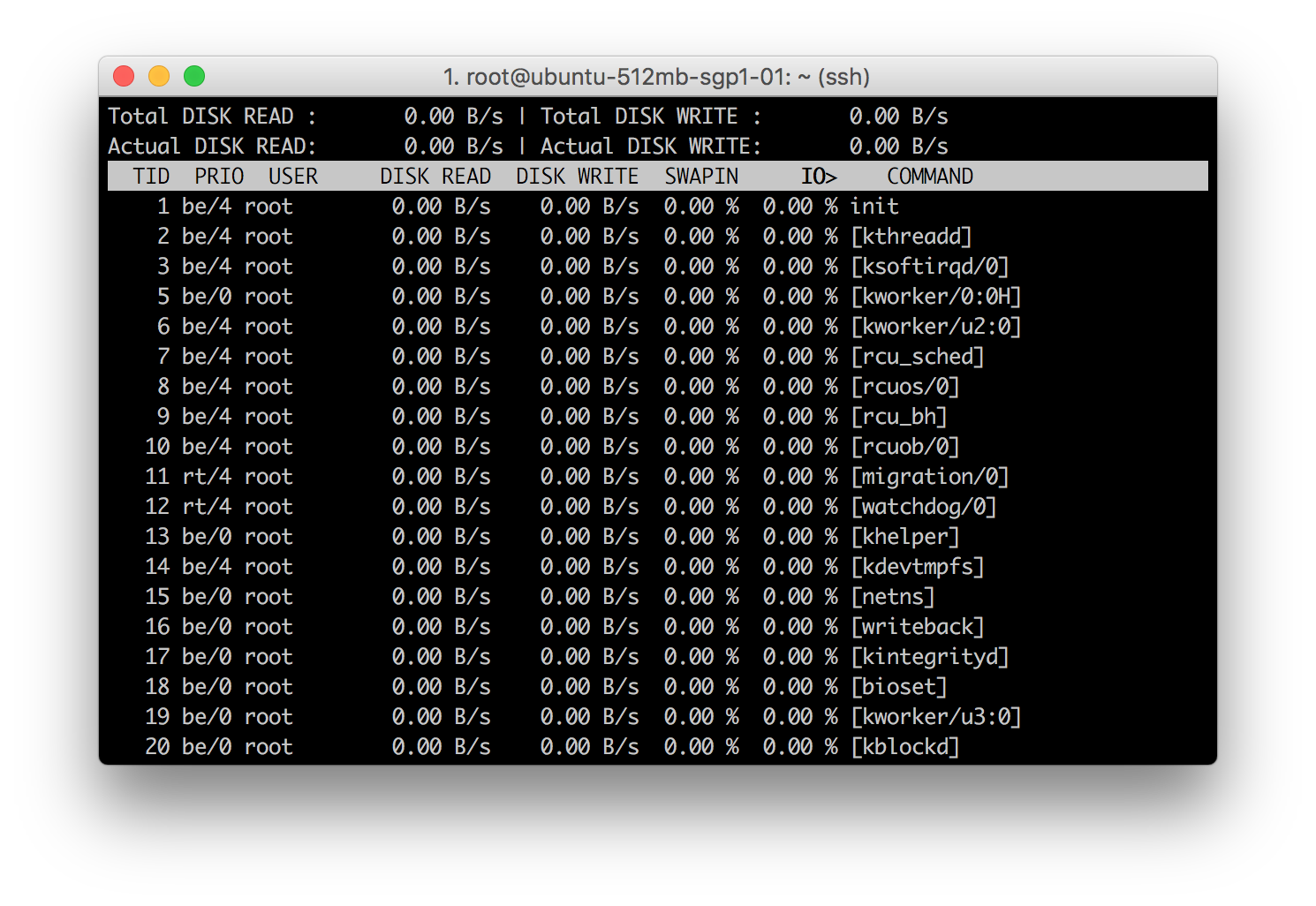
iotop в виде столбцов отображает пропускную способность ввода/вывода, считываемую и записываемую каждым процессом/потоком в течение периода выборки. Также показывается процент времени, которое процесс/поток потратил на подкачку и ожидание ввода/вывода.
Итак, вышеизложенный материал показал, что мониторинг осуществляется очень просто. В Linux помимо уже предоставленных данных присутствуют также бесплатные программы и инструменты для мониторинга. Системному администратору остается только применить их таким образом, чтобы человеку, не разбирающемуся в технике, было легко и понятно.
Мониторинг действительно имеет много плюсов, а именно:
- Обеспечивает понимание и принятие решений на основе данных.
- Обнаруживает проблемы на раннем этапе, предотвращая более крупные неполадки.
- Улучшает продуктивность и производительность.
- Помогает спланировать и рассчитать стоимость обновления оборудования.
- Предотвращает и сокращает время простев, которые могут привести к коммерческим потерям.
Мониторинг компьютерной системы важен так же, как и сама система. Он необходим так же, как и тестирование приложений, развернутых в системе. С внедрением мониторинга начинается более «здоровая» жизнь для компьютерной инфраструктуры. И уже по мере развития сети можно не только применять различные стратегии, но и обязательно проводить настройку и постоянную модернизацию.
В большинстве случаев мониторинг всей сети и настройка полноценной сквозной системы уведомлений требует времени и усилий. Однако с правильными инструментами, должным пониманием всей инфраструктуры, стеком приложений в системе, а также решением, которое помогло вручную исправить проблему при ее возникновении системный мониторинг сможет, по крайней мере, снизить частоту возникновения проблем и, возможно, обучить систему, как действовать в подобном случае в следующий раз.
Источник:
- Руководство пользователя Linux: https://linux.die.net/man/









